
Quinstor is an extremely lightweight in-memory, queryable & indexable store.
It is designed to maximise the number of objects you can store and to minimise the amount of time required to query them.
Disclaimer - Quinstor is currently in a very early alpha state. It is currently free for development use only however at this time no support or warranties are offered. You can download the latest version from quinstor-0.0.1.jar. Quinstor uses Javassist as part of its query compilation optimisation which can be downloaded from its website or added using the Maven dependency:
<dependency>
<groupId>javassist</groupId>
<artifactId>javassist</artifactId>
<version>3.12.1.GA</version>
</dependency>
Why?
In short, because I couldn't believe the overheads imposed by some of the big names in in-memory storage and decided to see if it was possible to do better. During some work on memory density, I noticed that I was able to store far fewer objects in existing stores than I expected - in some cases by more than a factor of 2. Worse, the capacity reduced by 20% each time I added an index - even one with low cardinality.
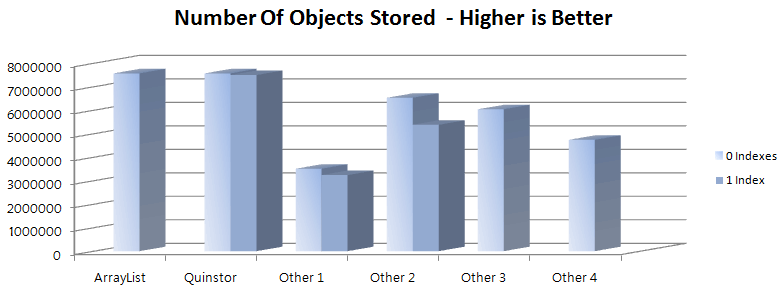
Quinstor proves that overhead is unnecessary - its native storage has virtually the same overhead as an ArrayList and it can query millions of objects per-second per-core - either via an OQL-like language or its own DSL. Its index support enables sub-millisecond queries despite the index consuming less than 1% of capacity even for high-cardinality/unique indexes.
The chart above compares Quinstor's storage to a number of other mainstream in-memory data stores. All were constrained to the same 4GB heap. For comparison, the same test was performed with an ArrayList - a dynamically sized container with one of the lowest overheads.
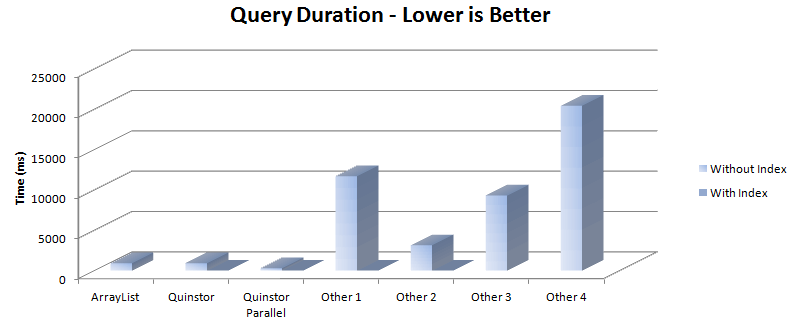
This chart compares the time to query 3 million objects in the same stores. The ArrayList implementation was a simple iterate over the contents with hand-crafted Java to query the object - the fastest we could expect without parallelism or indexes. Again, Quinstor comfortably outperforms the alternatives.
Basic Introduction
Creating the store is as simple as:
import com.andrewelmore.quinstor.Quinstor;
import static com.andrewelmore.quinstor.query.dsl.Query.*;
Quinstor<Type> quinstor = new Quinstor<>(Type.class, blockSize);
- Type is the type of object you wish to store and
- blockSize is the increments (number of objects) in which Quinstor will grow its internal store as more objects are added
and to add an object to the store:
quinstor.add(object);
Querying
Quinstor has both a DSL and an OQL query interface. Let's assume that our store is populated with objects of type Person:
public class Person {
public static class Name {
private String first;
private String last;
public String getFirst() {
return first;
}
public String getLast() {
return last;
}
}
private Name name;
private int age;
public Name getName() {
return name;
}
public int getAge() {
return age;
}
}
int count = quinstor.query(select(count("*"))
.where("name.last").is("Elmore"));
int count = quinstor.query(
"select count(*) where name.last = 'Elmore'"
);
Collection<String> names = quinstor.query(
"select name.first where age in (20, 21)"
);
for(String name : names) {
...
}
quinstor.query("select mean(age) where name.first = 'John'");
// Find all objects with a first name of Matthew
//and pass their age and an in-scope object 'aLiteral' to method
java.lang.reflect.Method method = ...
quinstor.query(select(collect(
invoke(method, project("age"), aLiteral)
))
.where("name.first").is("Matthew"));
Going Faster
There are a number of ways to speed up your queries. The first is to compile them - this can have substantial gains, especially where projections are concerned. To compile the query, simply add the instruction to compile to the end:
quinstor.query(select(count("*")
.where("name.last").is("Elmore")
.compile(Person.class));
Finally of course there are indexes. Currently these need to be added before objects are added to Quinstor. 2 types of index are supported:
-
Balanced tree-based indexes. These are well-suited for low cardinality data:
quinstor.addIndex("age"); -
Hash-based indexes. These are well-suited for high-cardinality or unique data:
quinstor.addHashedIndex("name.first");
What's Next?
There are still a number of basic features missing from Quinstor and a lot of more advanced ones. Currently on my list are:
- Documentation!
- API improvements to simplify usage
- AND/OR support in predicates
- Standalone server (with network support)
- Replication
- Registering a listener (with a predicate) to be informed of new objects as they're added
- Further compilation enhancements - the further up the tree we push compilation, the faster it runs